Google Scholar 2017学术指标之人工智能篇
2017年 7月 9号近日,Google Scholar发布了一个2017年的“学术指标”,主要是对各个学科的众多领域的学术刊物(包括期刊、会议论文集以及在线论文出版集)做出了排名。这个排名主要是依靠H5-Index这一指标。我们在这篇文章里,对人工智能相关的领域学术出版刊物的排名进行一个简单的分析和导读。
人工智能主类
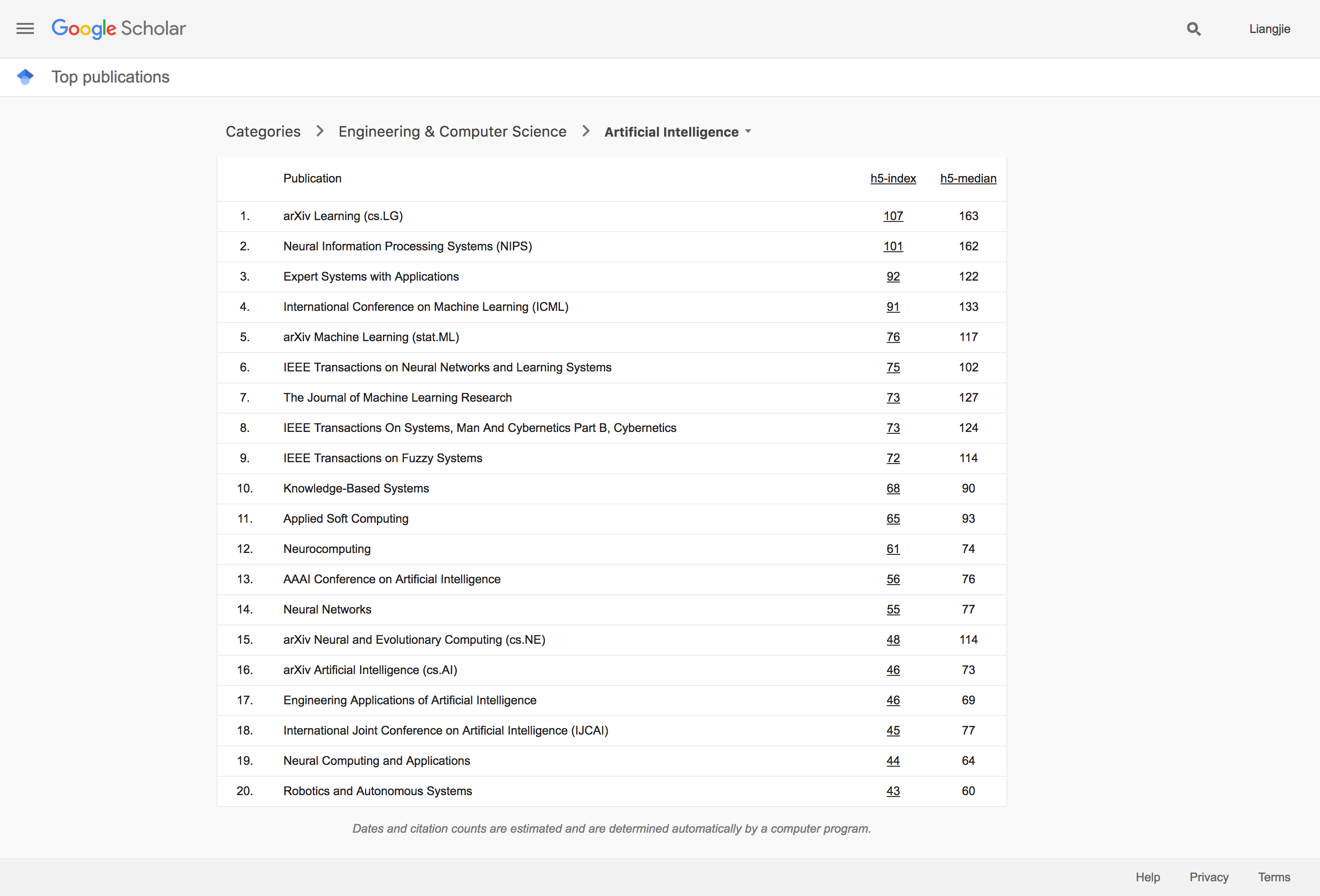 因为收率了在线论文出版集(主要是ArXiv),借着深度学习(Deep Learning)的春风,ArXiv的Learning子类成为了目前最有影响力的出版集。当然,考虑到目前在深度学习以及更加广阔的机器学习领域已经有了把论文的某一个版本率先发表到ArXiv的习惯,Learning子类的实际影响力可能要打一些折扣。不过,不可否认的则是这样的发布学术结果的方式的确对计算机科学(Computer Science)原本的发表模式有了很深远的挑战和影响。
因为收率了在线论文出版集(主要是ArXiv),借着深度学习(Deep Learning)的春风,ArXiv的Learning子类成为了目前最有影响力的出版集。当然,考虑到目前在深度学习以及更加广阔的机器学习领域已经有了把论文的某一个版本率先发表到ArXiv的习惯,Learning子类的实际影响力可能要打一些折扣。不过,不可否认的则是这样的发布学术结果的方式的确对计算机科学(Computer Science)原本的发表模式有了很深远的挑战和影响。
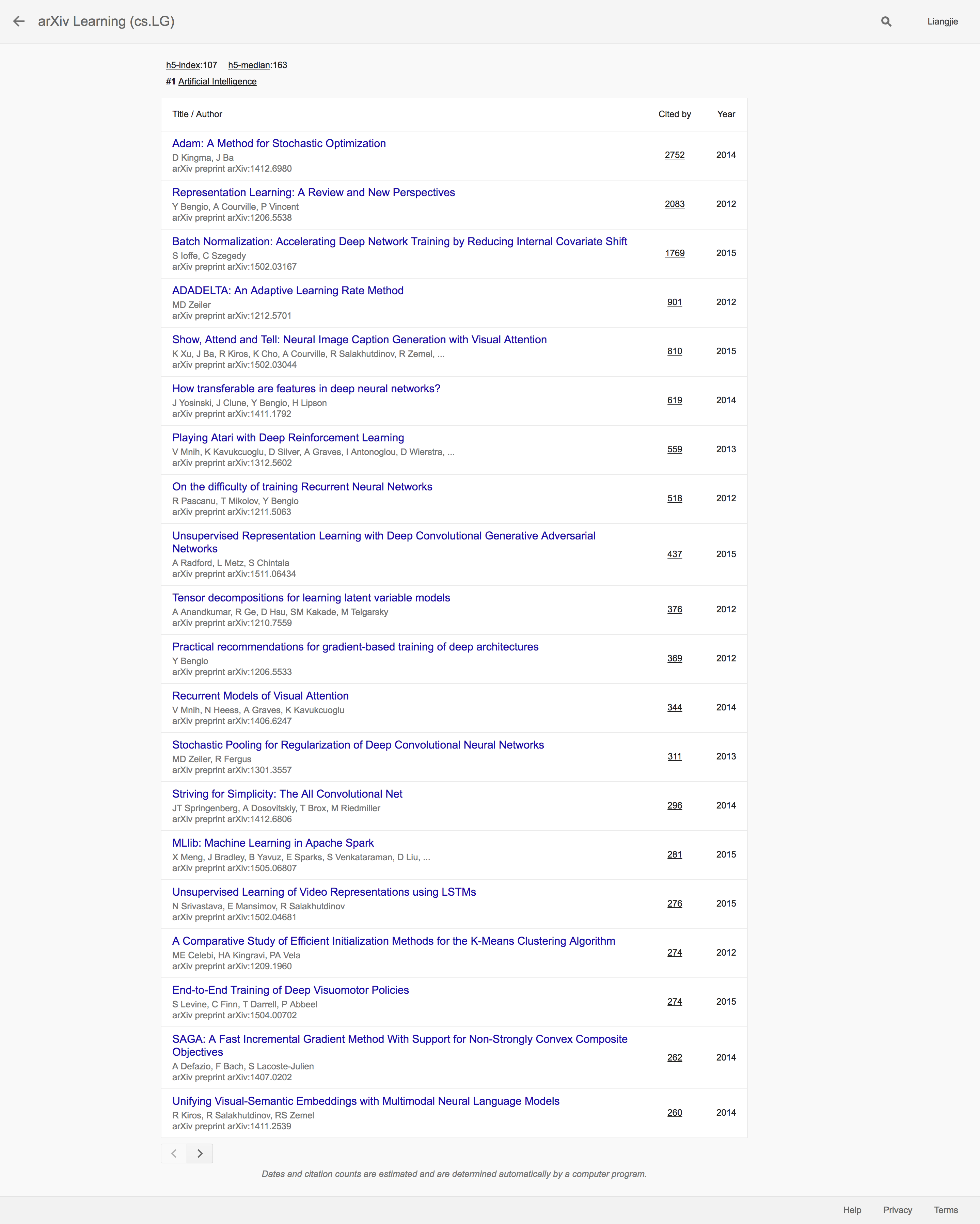 有意思的是,尽管引用度排名靠前的大多数文章最终都在传统的会议或者期刊上面发表,排名第四的ADADELTA: An Adaptive Learning Rate Method(应用数超过900)则并没有在任何传统刊物上有出版。还有引用度超过500的Playing Atari with Deep Reinforcement Learning也没有在传统的刊物上发表出版。这些都显示了ArXiv作为当前出版渠道的重要补充的这一作用。我们再来看一下传统刊物中排名第一的NIPS的排名靠前的文章:
有意思的是,尽管引用度排名靠前的大多数文章最终都在传统的会议或者期刊上面发表,排名第四的ADADELTA: An Adaptive Learning Rate Method(应用数超过900)则并没有在任何传统刊物上有出版。还有引用度超过500的Playing Atari with Deep Reinforcement Learning也没有在传统的刊物上发表出版。这些都显示了ArXiv作为当前出版渠道的重要补充的这一作用。我们再来看一下传统刊物中排名第一的NIPS的排名靠前的文章:
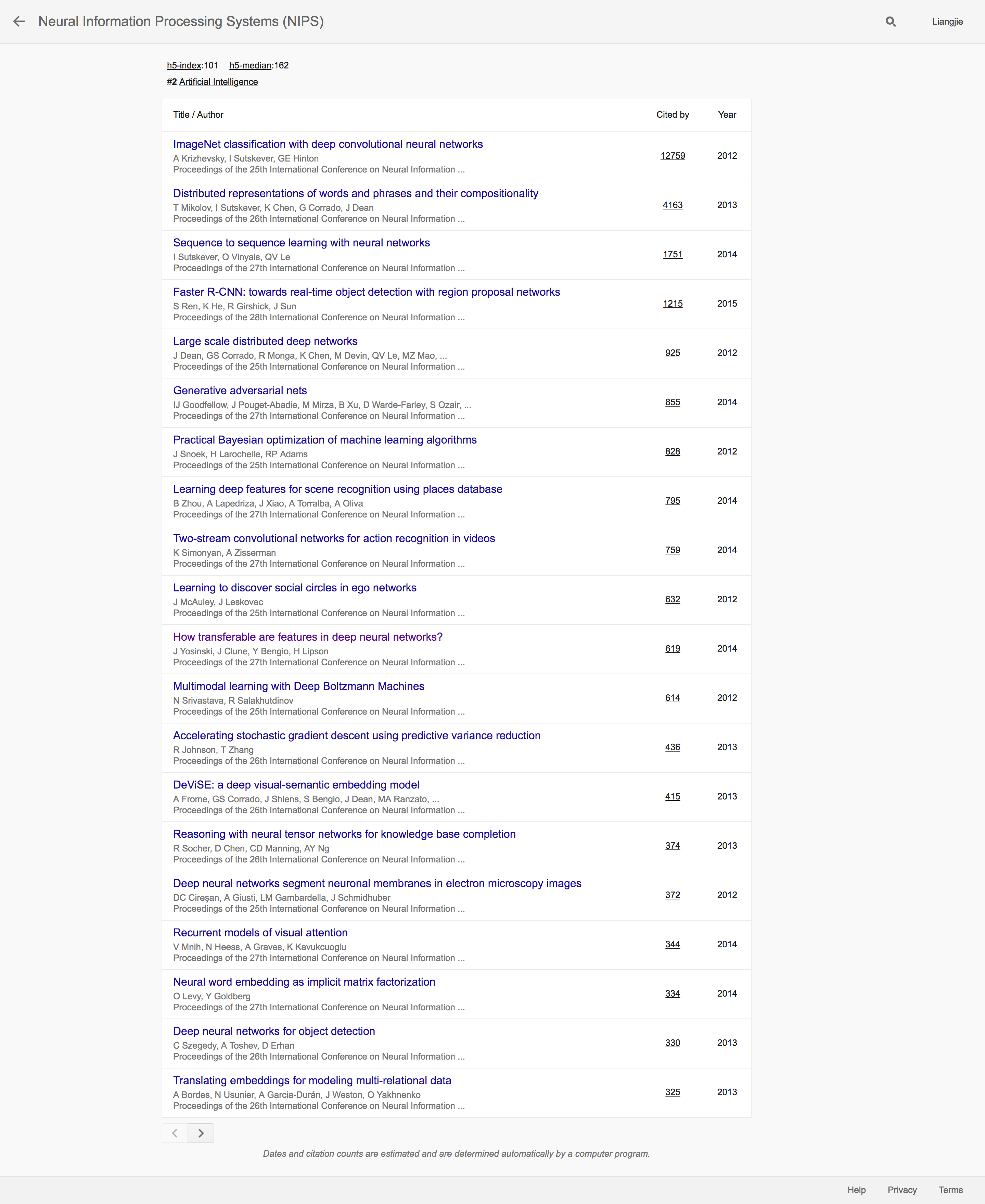 首先我们发现的是,排名靠前的无一例外地都是和深度学习有密切联系的文章。排名第一的则是Hinton及其学生提出的AlexNet的这一开创性的研究成果,一举奠定了深度学习在计算机视觉领域的主导地位的历史性文章。排名第二的则是提出目前在NLP等领域广泛使用的Word2Vec的论文,也可以说实至名归。总之,NIPS排名靠前的论文还是非常有含金量的标志性研究成果。和NIPS齐名的机器学习会议ICML也在排名上位列第4。
首先我们发现的是,排名靠前的无一例外地都是和深度学习有密切联系的文章。排名第一的则是Hinton及其学生提出的AlexNet的这一开创性的研究成果,一举奠定了深度学习在计算机视觉领域的主导地位的历史性文章。排名第二的则是提出目前在NLP等领域广泛使用的Word2Vec的论文,也可以说实至名归。总之,NIPS排名靠前的论文还是非常有含金量的标志性研究成果。和NIPS齐名的机器学习会议ICML也在排名上位列第4。
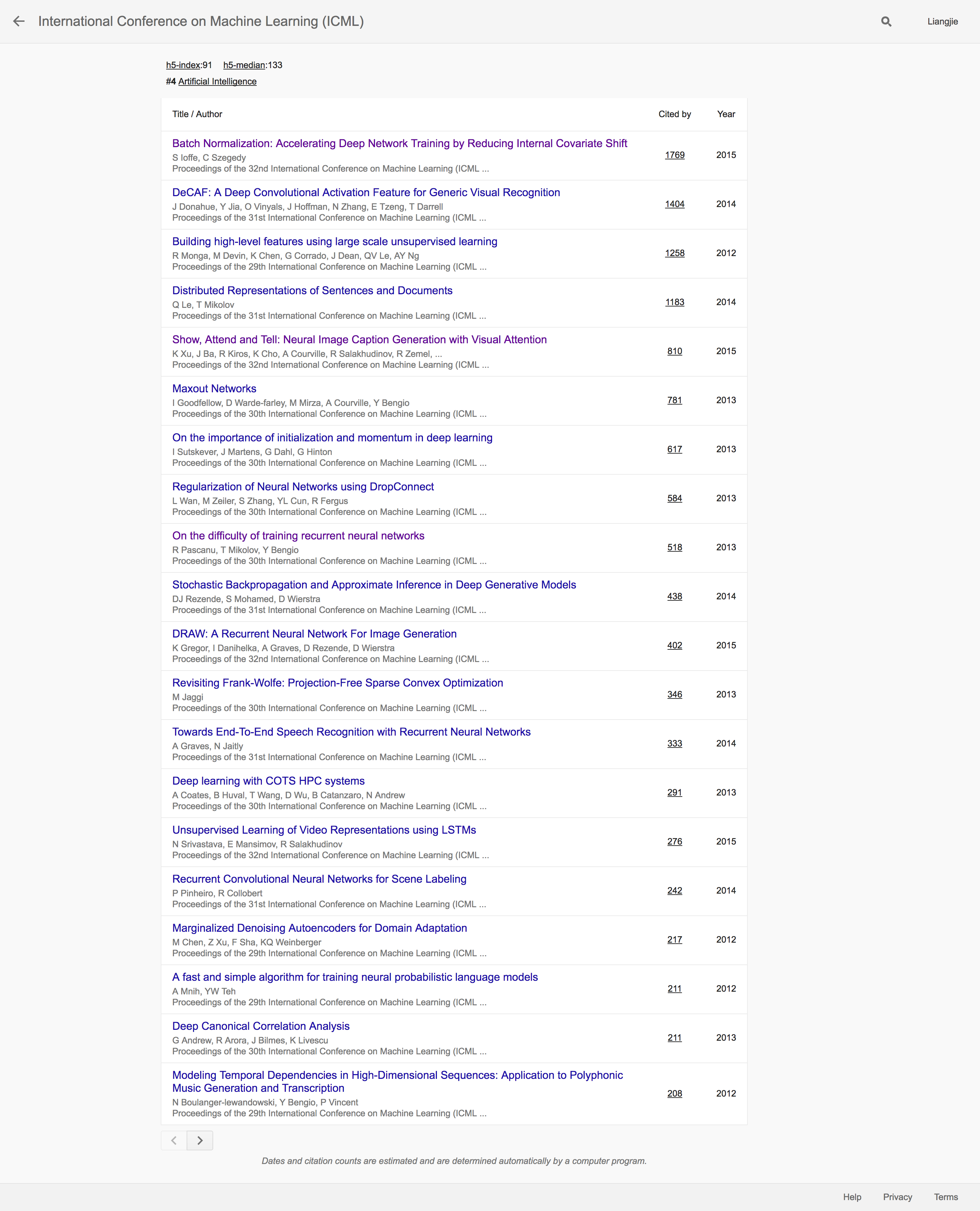 和NIPS类似的也是排位靠前的文章基本上被深度学习相关的研究成果所把持。相比之下,排位稍微靠后的期刊IEEE Transactions on Neural Networks and Learning Systems以及The Journal of Machine Learning Research则多了不少机器学习其他领域的研究成果。
和NIPS类似的也是排位靠前的文章基本上被深度学习相关的研究成果所把持。相比之下,排位稍微靠后的期刊IEEE Transactions on Neural Networks and Learning Systems以及The Journal of Machine Learning Research则多了不少机器学习其他领域的研究成果。
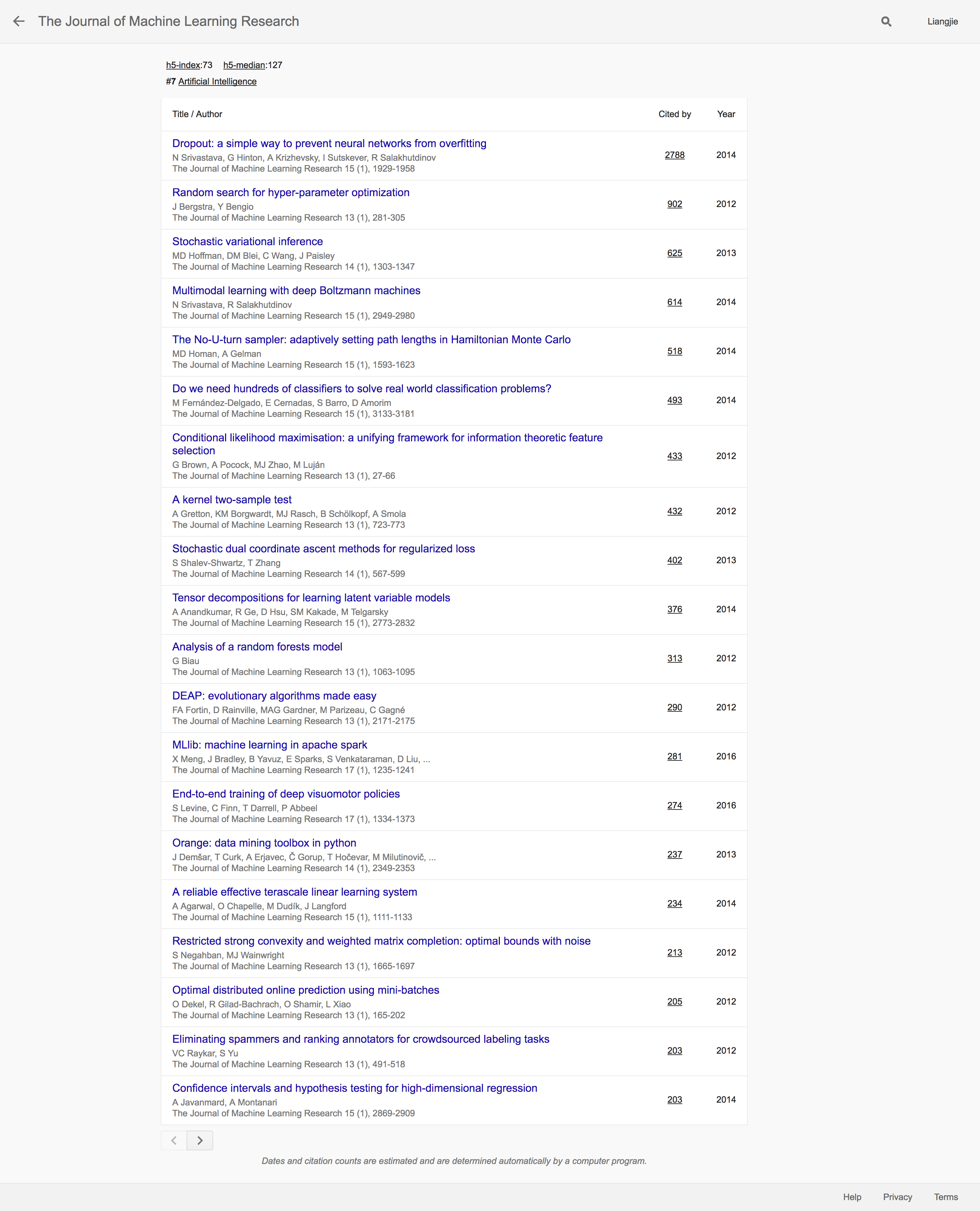 比如,最近几年又重新红火起来的大规模Bayesian Inference的代表作Stochastic variational inference以及开创了Moment Matching旧瓶装新酒的Tensor decompositions for learning latent variable models也都名列前茅。通过我们这里简单的分析和总结,不难发现最近五年AI界的成果还是集中在深度学习界,而且是传统刊物NIPS和ICML都成为了推动深度学习发展的重要领军会议。而ArXiv则在这个过程中发挥着不可替代的辅助性作用。
比如,最近几年又重新红火起来的大规模Bayesian Inference的代表作Stochastic variational inference以及开创了Moment Matching旧瓶装新酒的Tensor decompositions for learning latent variable models也都名列前茅。通过我们这里简单的分析和总结,不难发现最近五年AI界的成果还是集中在深度学习界,而且是传统刊物NIPS和ICML都成为了推动深度学习发展的重要领军会议。而ArXiv则在这个过程中发挥着不可替代的辅助性作用。
计算机视觉
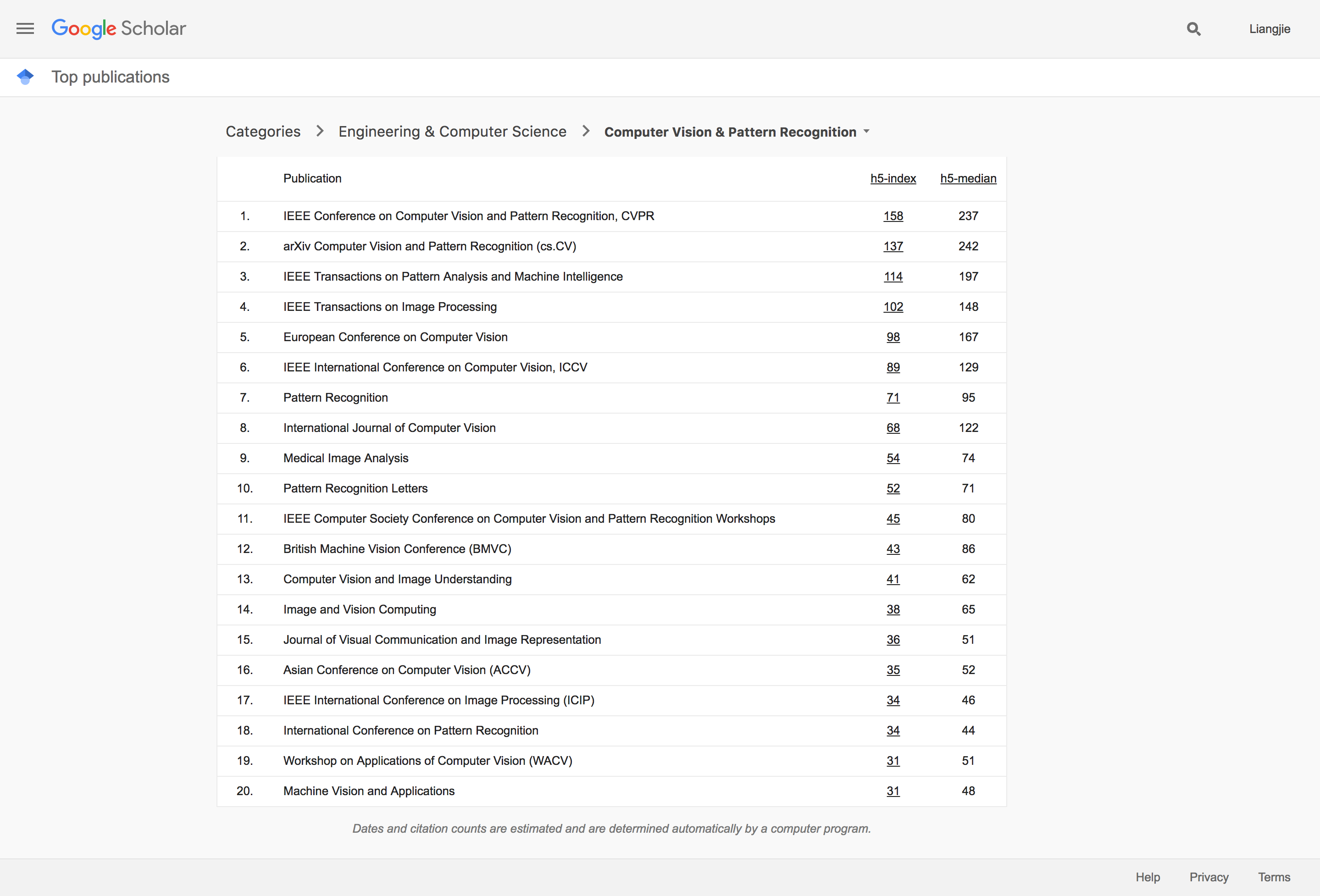 我们看了人工智能主类之后,我们来关注一下几个人工智能的分类的动态。那么要说最近几年发展得最迅猛的人工智能分支,无疑要数计算机视觉技术。不过,相比于人工智能主类的好几大主流会刊的情况,在计算机视觉领域,目前的格局依然是CVPR和PAMI独秀的情况。而ArXiv的补充作用在这里也显示得很明显。
我们看了人工智能主类之后,我们来关注一下几个人工智能的分类的动态。那么要说最近几年发展得最迅猛的人工智能分支,无疑要数计算机视觉技术。不过,相比于人工智能主类的好几大主流会刊的情况,在计算机视觉领域,目前的格局依然是CVPR和PAMI独秀的情况。而ArXiv的补充作用在这里也显示得很明显。
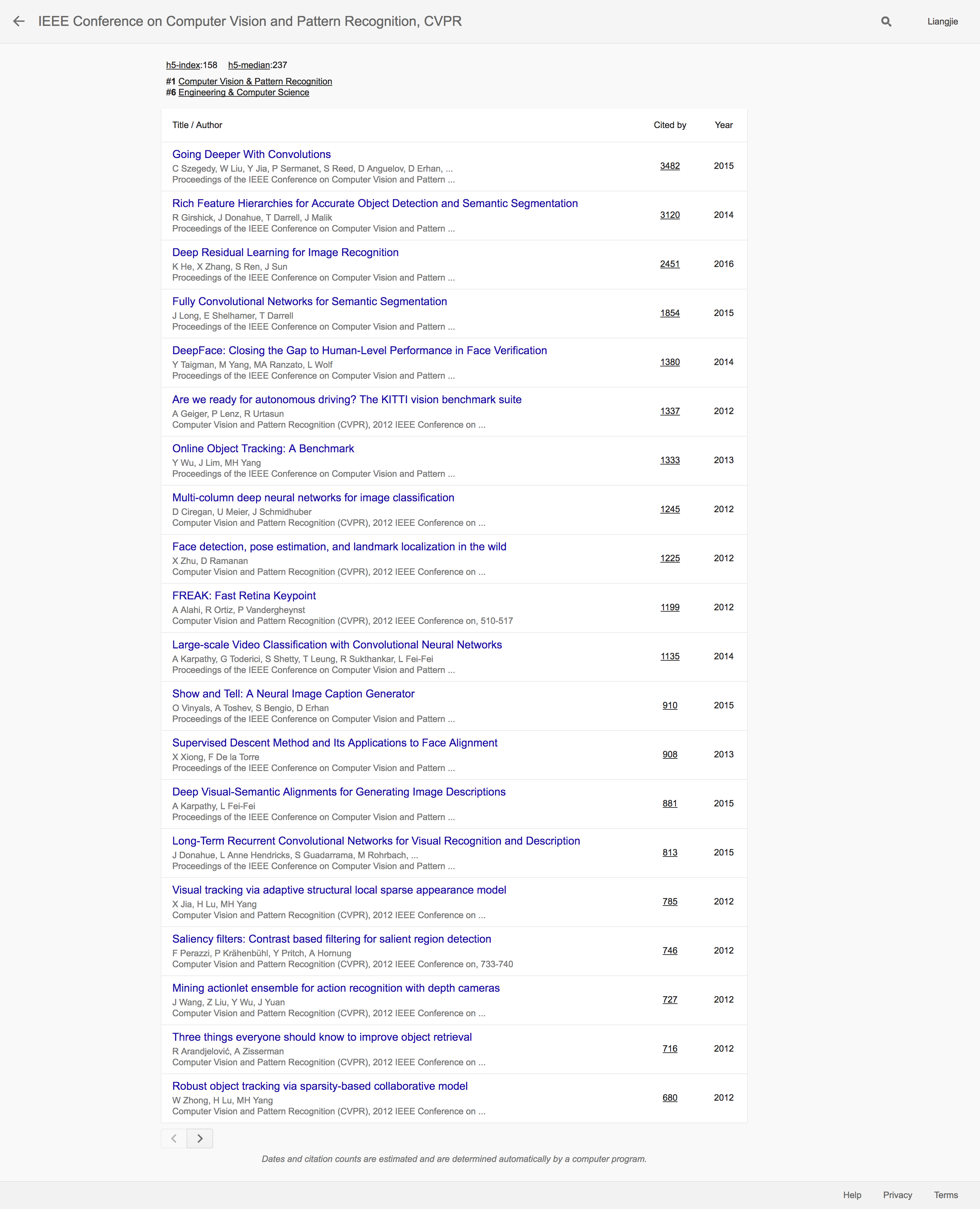 我们来看看CVPR的这几年的有影响力的工作,无疑都和ImageNet的主要进步联系起来。比如排名第一的Going Deeper With Convolutions所代表的GoogleNet,以及排名第二的Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation所提出的R-CNN和排名第三的Deep Residual Learning for Image Recognition所提出的ResNet。这些都是最近几年借助大幅度提高ImageNet的效果而在CV领域获得重点关注的文章。
我们来看看CVPR的这几年的有影响力的工作,无疑都和ImageNet的主要进步联系起来。比如排名第一的Going Deeper With Convolutions所代表的GoogleNet,以及排名第二的Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation所提出的R-CNN和排名第三的Deep Residual Learning for Image Recognition所提出的ResNet。这些都是最近几年借助大幅度提高ImageNet的效果而在CV领域获得重点关注的文章。
计算语言学
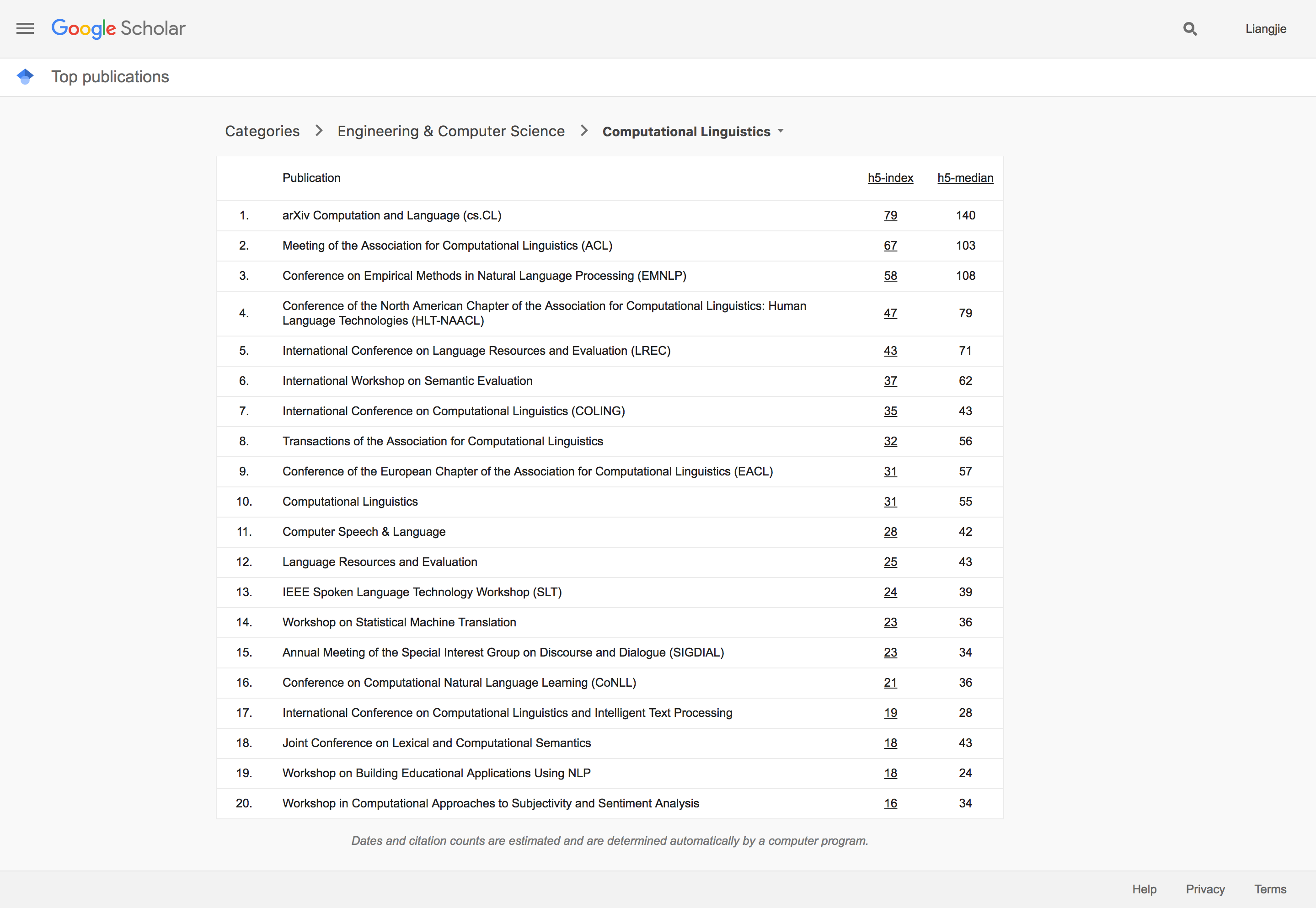 人工智能在计算语言学的应用主要体现在自然语言处理(NLP)等领域。借着深度学习在NLP领域的影响和发展,ArXiv成为一个主要的文章发表场所似乎也是顺利成长的事情了。和人工智能主类相似的情况是,在ArXiv上面发布的重要文章最后都在相应的会议或者期刊有所发表,唯一例外的是有3600多引用的Efficient Estimation of Word Representations in Vector Space。从分布的情况上看,过去几年的大多数影响力大的文章主要分为在Word2Vec方面做文章,以及在Machine Translation或者Sequence Model方面做文章。排名第二第三的依然是NLP领域传统的旗舰会议ACL和EMNLP。
人工智能在计算语言学的应用主要体现在自然语言处理(NLP)等领域。借着深度学习在NLP领域的影响和发展,ArXiv成为一个主要的文章发表场所似乎也是顺利成长的事情了。和人工智能主类相似的情况是,在ArXiv上面发布的重要文章最后都在相应的会议或者期刊有所发表,唯一例外的是有3600多引用的Efficient Estimation of Word Representations in Vector Space。从分布的情况上看,过去几年的大多数影响力大的文章主要分为在Word2Vec方面做文章,以及在Machine Translation或者Sequence Model方面做文章。排名第二第三的依然是NLP领域传统的旗舰会议ACL和EMNLP。

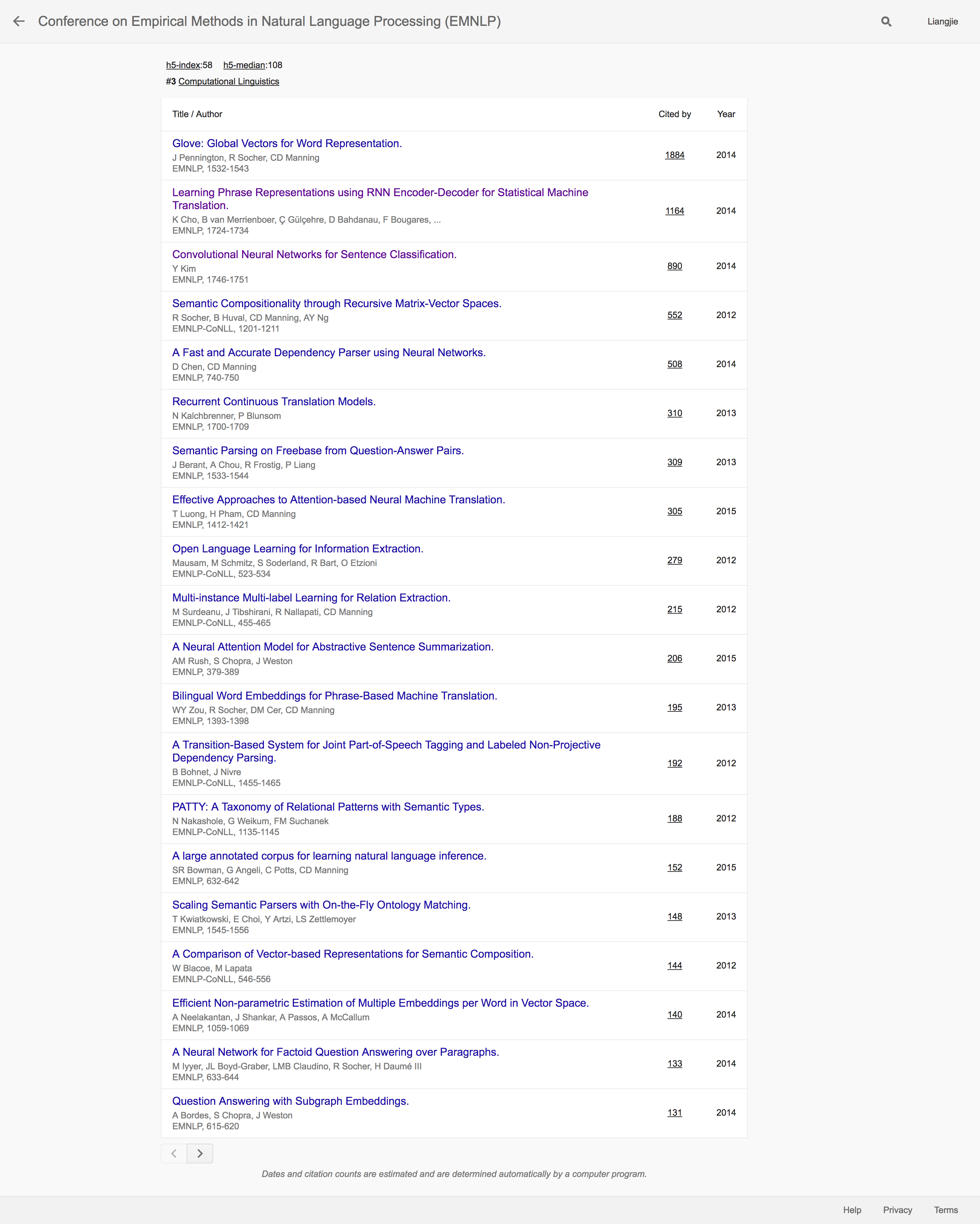 我们可以看到深度学习,特别是学习文字的Embedding(包括字、文章段落等等)占据了很重要的一个研究方向。另外一个重要的研究方向就是机器翻译,特别是如何应用深度学习在这方面的成果。需要特别注意的是,斯坦福大学Christopher Manning的研究组最近几年可以说是成果颇丰。高排名的好几篇ACL以及EMNLP都看得见他的身影。
我们可以看到深度学习,特别是学习文字的Embedding(包括字、文章段落等等)占据了很重要的一个研究方向。另外一个重要的研究方向就是机器翻译,特别是如何应用深度学习在这方面的成果。需要特别注意的是,斯坦福大学Christopher Manning的研究组最近几年可以说是成果颇丰。高排名的好几篇ACL以及EMNLP都看得见他的身影。
数据挖掘和信息系统
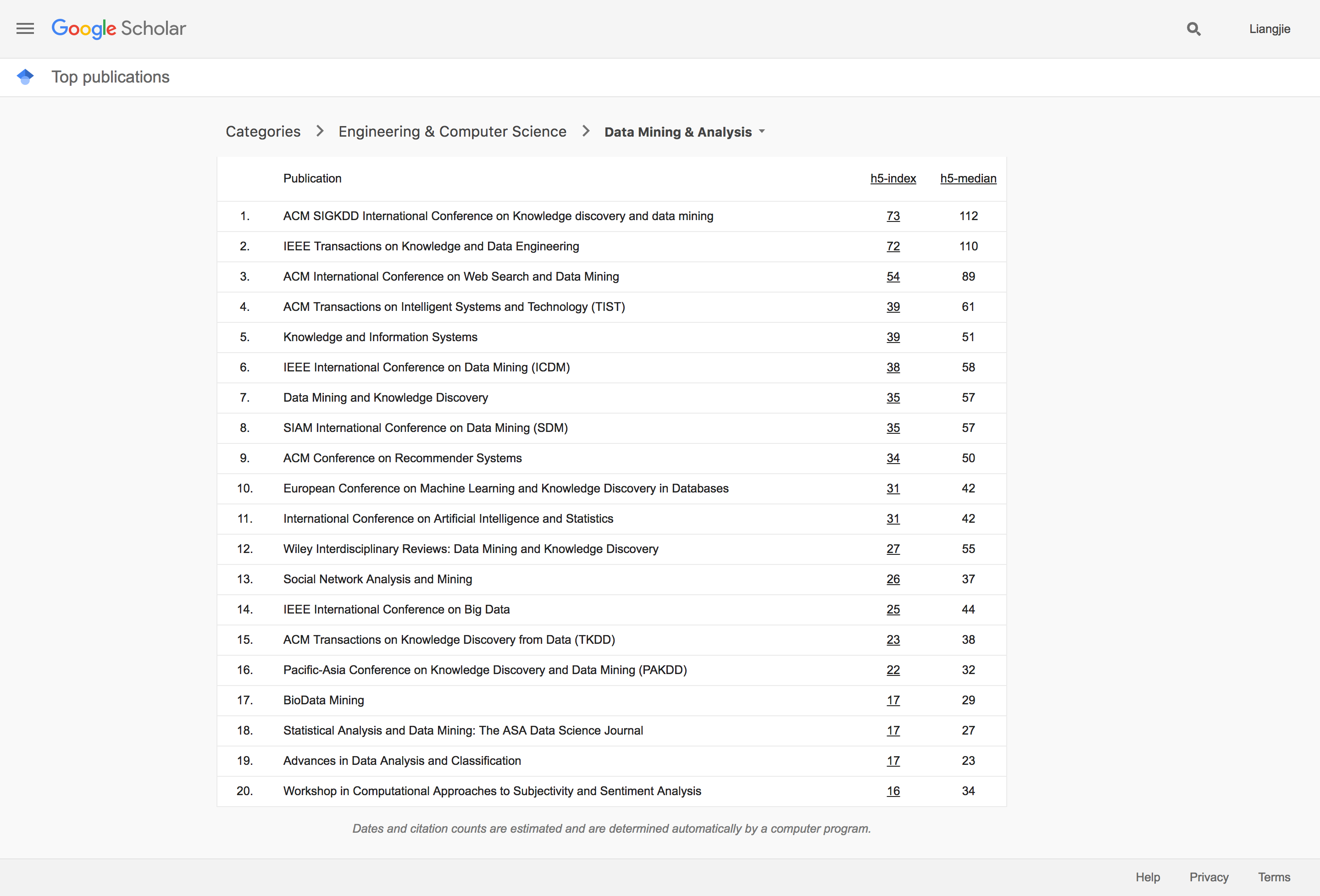
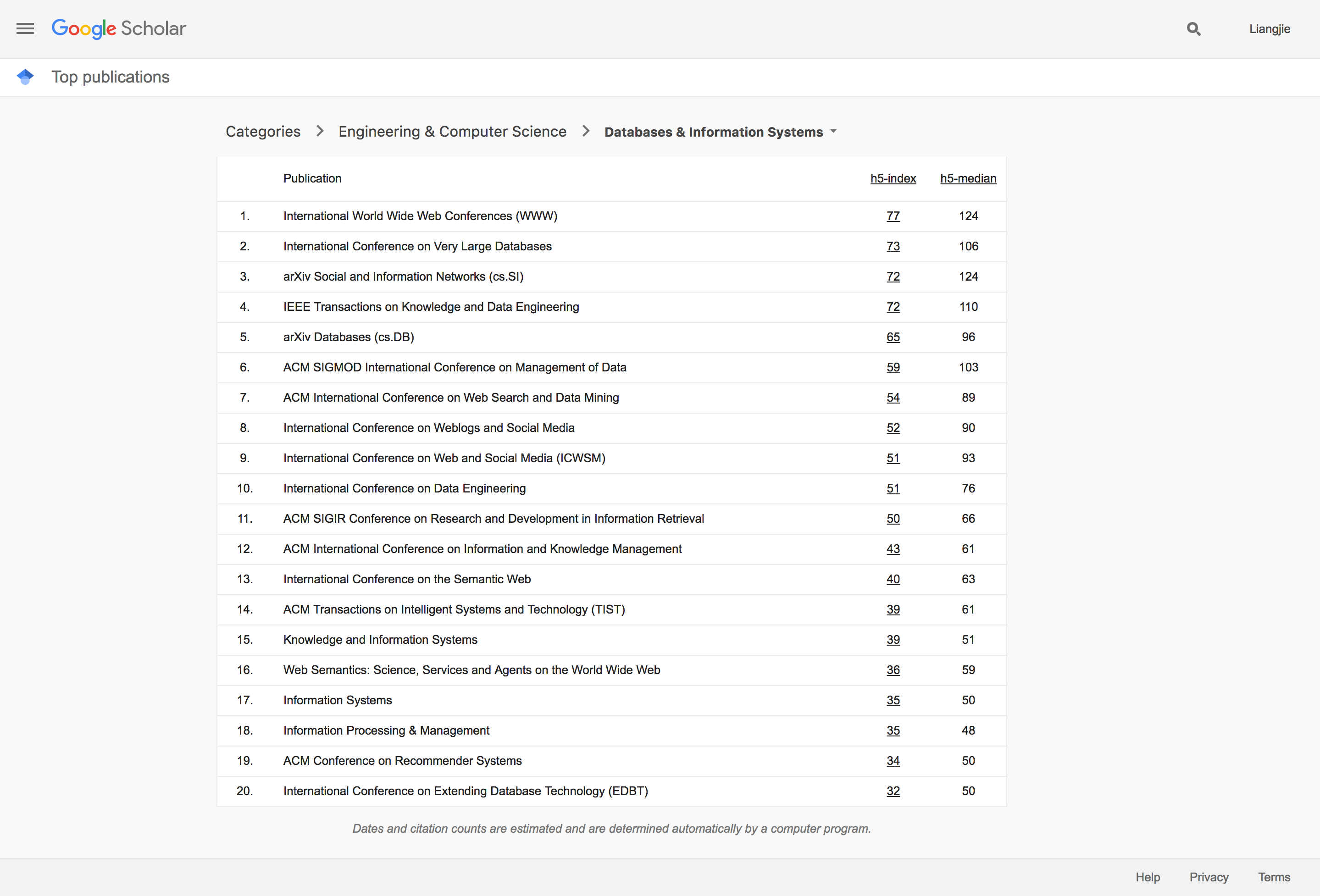 Google把整个数据挖掘和信息系统分为了两类“Data Mining & Analysis”和“Database & Information Systems”。然而在实际中这两类的文章和成果经常交叉出现,于是我们这里就一起讨论这两个分类。一个比较有意思的情况就是,ArXiv还并没有成为这个领域的主要发布工具。传统的KDD以及WWW依然占据着重要的成果发布平台的地位。我们来看一下KDD的最新经典论文:
Google把整个数据挖掘和信息系统分为了两类“Data Mining & Analysis”和“Database & Information Systems”。然而在实际中这两类的文章和成果经常交叉出现,于是我们这里就一起讨论这两个分类。一个比较有意思的情况就是,ArXiv还并没有成为这个领域的主要发布工具。传统的KDD以及WWW依然占据着重要的成果发布平台的地位。我们来看一下KDD的最新经典论文:
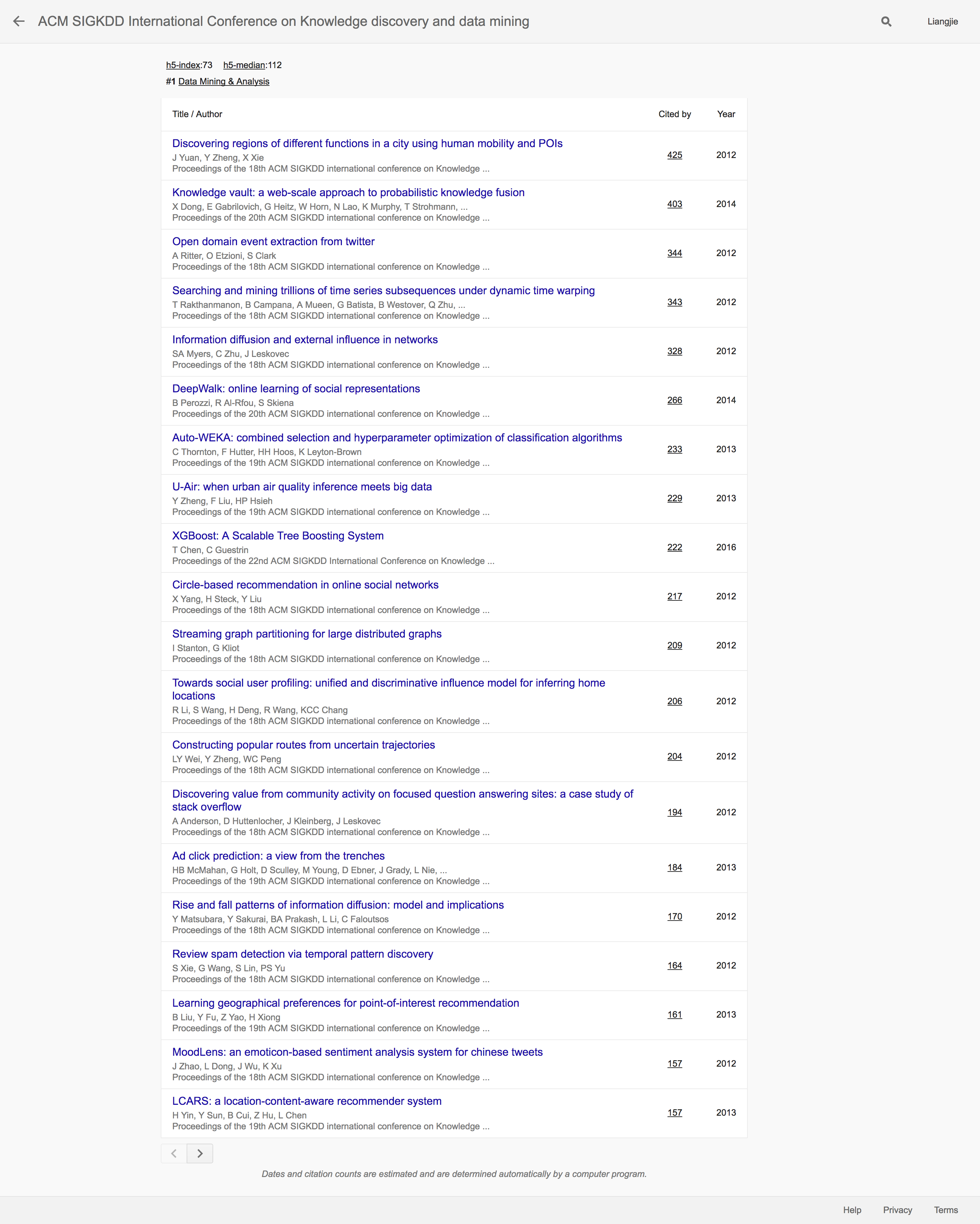 可以说是涉及范围十分广泛。从Social Network Analysis到Time Series Analysis再到一般性质的Data Mining的算法和工具,KDD还是展现了这个发布平台的包容性和多样性。其中排名第二的Knowledge vault: a web-scale approach to probabilistic knowledge fusion,这一讲述Google的知识图谱的技术论文和在2016年才发表的XGBoost: A Scalable Tree Boosting System在短时间内吸引了不少相关学者的关注。下面我们来看看WWW的情况:
可以说是涉及范围十分广泛。从Social Network Analysis到Time Series Analysis再到一般性质的Data Mining的算法和工具,KDD还是展现了这个发布平台的包容性和多样性。其中排名第二的Knowledge vault: a web-scale approach to probabilistic knowledge fusion,这一讲述Google的知识图谱的技术论文和在2016年才发表的XGBoost: A Scalable Tree Boosting System在短时间内吸引了不少相关学者的关注。下面我们来看看WWW的情况:
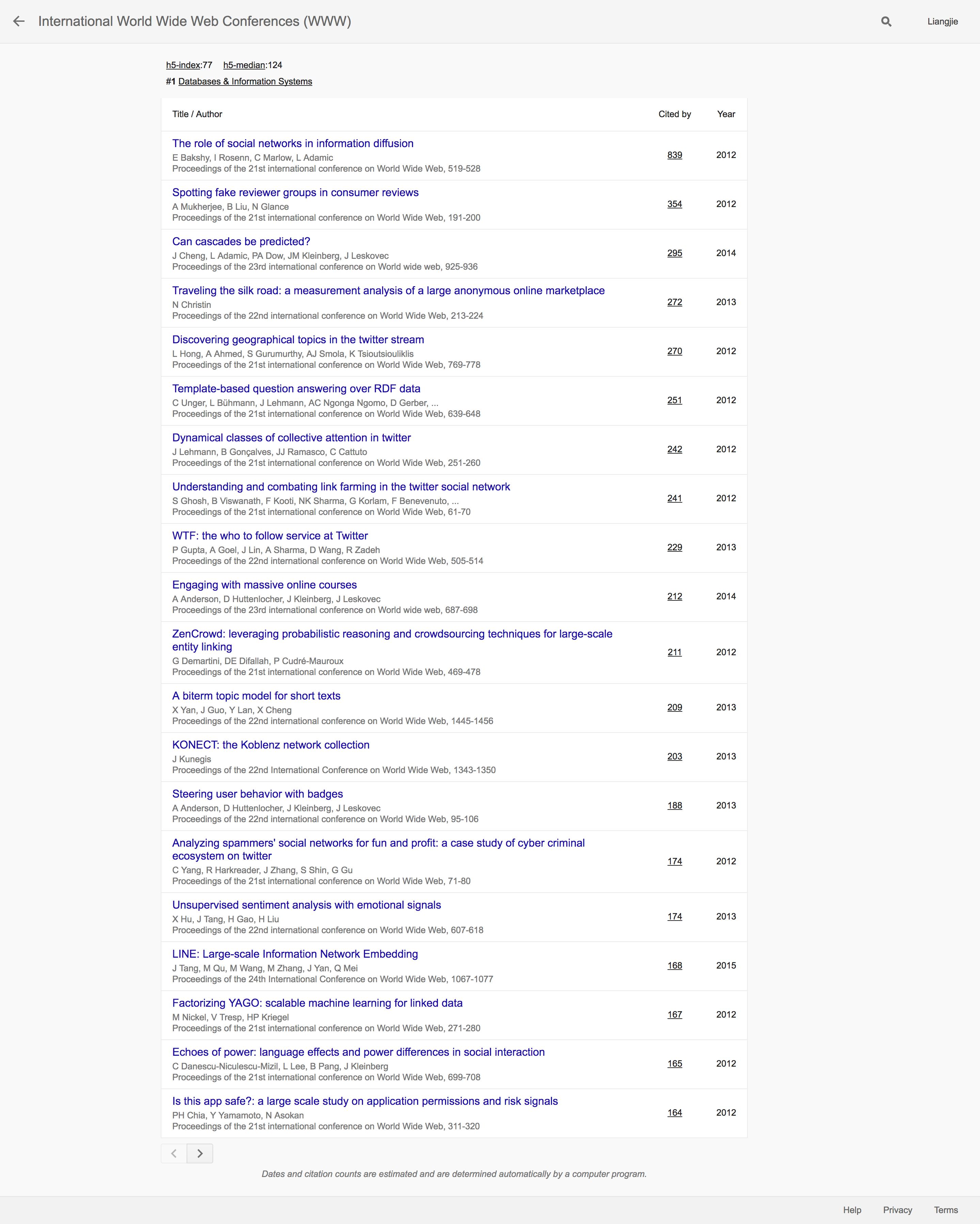 可以看出过去5年来,关于Social Media(以Twitter为主)和关于Social Network Analysis的相关研究还是如火如荼。而纵观KDD和WWW都可以看到斯坦福大学的明星学者Jure Leskovec的强大存在。
可以看出过去5年来,关于Social Media(以Twitter为主)和关于Social Network Analysis的相关研究还是如火如荼。而纵观KDD和WWW都可以看到斯坦福大学的明星学者Jure Leskovec的强大存在。
总结
我们仅仅是在这里总结了和人工智能有关的几个分类的趋势。总体说来有这么几个特点:
- 人工智能和机器学习的核心领域目前基本上完全围绕着深度学习展开。
- 计算机视觉和自然语言处理目前也是和深度学习有很强的联系。
- 数据挖掘相关的研究依然非常多样化。
- ArXiv已经成为了非常强有力的辅助性研究成果发布平台。然而有影响力的文章最终还是在核心刊物上发表。
- 传统的NIPS、ICML、CVPR、ACL、EMNLP、KDD和WWW依然是人工智能的核心研究成果发布刊物。